
The Future of Database Systems
What is wrong with the current Database Systems?
The IT industry has used Relational Database Systems (RDBMS) since the ’70s. But as the industry grew in modern times, Web 2.0 and Social Networking innovations have drastically changed the requirements for a traditional database. Even though modern Relational Database systems can withstand their very high needs to some degree, the next generation of innovative technologies is always limited by the following factors:
- The extent to which the current Relational Database systems can scale up to meet their demands.
- The costs associated with the level of scale-up that would be required.
- Whether the innovators of said technologies can afford to pay those costs.
- Even after an expensive scale-up to meet their requirements, how sustainable the whole setup is and for how long.
The term NoSQL (meaning non-SQL) was suggested in 1998 to support a new Database technology that does not use the Structured Query Language (SQL) interface, which was the standard used by most RDBMS systems until then. However, the new Database technology in question was still using the relational model and was not addressing the growing challenges. So, the industry has already started working toward what is next after the Relational Database systems that can handle the ever-increasing challenges with RDBMS systems.
Again, in early 2009 the same NoSQL term was reintroduced to address the growing open-source, distributed, and non-relational Databases. The new NoSQL Database systems used document-based models such as Key-Value Store to address the ever-increasing challenges in the industry. They were pretty good at handling the large volume of Data requirements in a highly distributed and unlimited scalable way. They brought forth the emergence of Big Data systems.
However, the NoSQL systems that had ridden the relational data models faced new challenges in representing relational or inter-connected data. They had to implement various technical trickery to address those challenges, none of which addressed the underlying problem they were facing: native representation of relational or inter-connected data. That was the main problem, to begin with, that has existed since the dawn of Database systems.
So, the industry slowly shifted focus to a technology that had existed since the late ’60s. Graph Database that uses Graph structure or Graph model to represent related or inter-connected data. However, it wasn’t until the late ‘2000s that commercially usable, ACID-compliant databases, such as Neo4j, became available that the industry started towards a new journey of high-performance, highly scalable, and natively represented relational databases that would be the future of all Database systems.
Why would we care about Graph Database Technology?
The challenges faced by both the RDBMS systems and their next-generation NoSQL systems, even with Big Data technology, were all addressed by Graph Database technology in the following ways:
Performance:
The data volume will increase in the future, but what’s going to increase at an even faster rate is the connections (or relationships) between the data. Big data will definitely get bigger, but connected data will grow exponentially. With traditional databases, relationship queries come to a grinding halt as the number and depth of relationships increase. In contrast, Graph database performance stays constant even as the data grows year over year.
Flexibility:
With Graph databases, IT and data architecture teams move at the speed of business because the structure and schema of a graph data model flex as the solutions and industry change. They don’t have to exhaustively model the domain ahead of time (and then exhaustively remodel and migrate the DB after some executive asks for a change); instead, they can add to the existing structure without endangering current functionality.
With the Graph database model, Users are the ones dictating changes and taking charge, whereas the RDBMS data model dictates its requirements to Users, forcing them to adapt to its tabular way of seeing the world.
Agility:
Developing with Graph technology aligns perfectly with today’s agile, test-driven development practices, allowing emerging graph-database-backed applications to evolve with their changing business requirements. The agile teams now have a database that keeps up with their daily demands.
What is a Graph Database? (a Non-Technical Definition)
We don’t need to understand the arcane mathematical wizardry of Graph theory to understand Graph database technology. On the contrary, they’re more intuitive to understand than Relational databases (RDBMS).
A Graph is composed of two elements: a Node and a Relationship.
Each Node represents an Entity (a person, place, thing, category, or other pieces of data), and each Relationship represents how two Nodes are associated. For example, the two nodes Cake and Dessert would have the Relationship is a type of pointing from Cake to Dessert.
Consider another example: Twitter is a perfect example of a graph database connecting 200+ million daily active users.
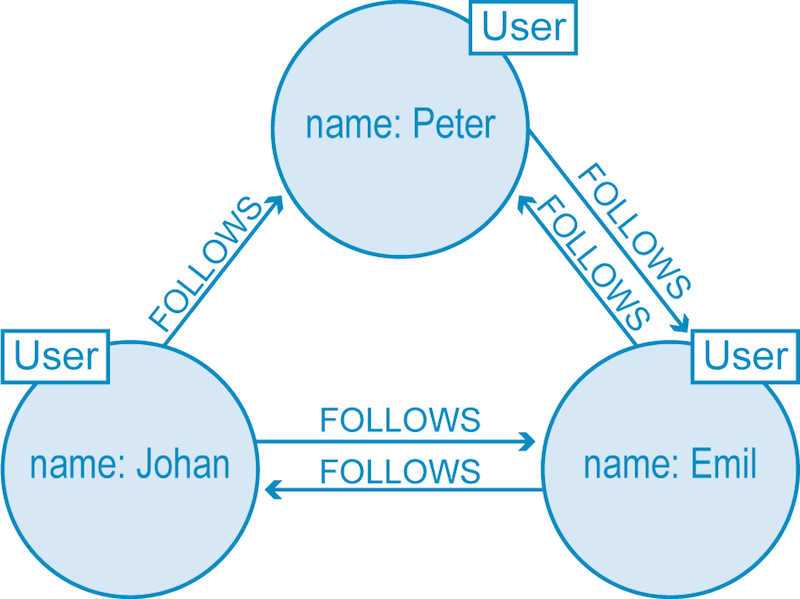
The illustration below shows a small slice of Twitter users represented in a Graph database. Each Node (labeled User) belongs to a single person and is connected with relationships describing how each user is connected. As we see below, Peter and Emil follow each other, as do Emil and Johan, but although Johan follows Peter, Peter hasn’t (yet) reciprocated.
How do Graph Databases work?
Unlike other Database Management Systems (DBMS), relationships take first priority in Graph databases. In the Graph world, connected data is equally (or more) important than individual data points.
This connections-first approach to data means relationships and connections are persisted (and not just temporarily calculated) through every part of the data lifecycle: from idea to design in a logical model, to implementation in a physical model, to operation using a query language and to persistence within a scalable, reliable Database system.
Unlike other Database systems, this approach means our applications don’t have to infer data connections using things like foreign keys or out-of-band processing, like MapReduce.
The result: Our data models are simpler yet more expressive than those we’d produced with relational Databases or NoSQL (Not only SQL) stores.
What Makes Graph Databases Unique
Many databases have similar characteristics, but Graph databases have a few things that make them unique. Here are the two most important properties of Graph database technologies:
Graph storage
Some Graph databases use native Graph storage specifically designed to store and manage Graphs – from bare metal on up. Other Graph technologies use relational, columnar, or object-oriented databases as their storage layer. Non-native storage is often slower than a native approach because all Graph connections must be translated into a different data model.
Graph processing
Native Graph Processing (a.k.a. index-free adjacency) is the most efficient way to process data in a Graph because connected nodes physically point to each other in the database. Non-native Graph processing engines use other means to process Create, Read, Update or Delete (CRUD) operations that aren’t optimized for handling connected data.
Regarding current Graph database technologies, Neo4j leads the space as the most native when it comes to both Graph storage and processing.
Conclusion: Graphs are in more Places than You Think (They’re Everywhere)
The real world is richly interconnected, and Graph databases aim to mimic that sometimes-consistent, sometimes-erratic relationships intuitively. That’s what makes the Graph paradigm different than other database models: It maps more realistically to how the human brain maps and processes the world around it.
And once you start seeing Graphs of interconnected data in one place (your recommendation engine, for example), you start seeing them in other areas, too (like your fraud detection efforts or your master data management). Pretty soon, you’ll have the epiphany: Graphs are Everywhere!
It is no surprise then that Graph technology is rising (but you don’t have to take my word for it).
Exploring the Future of Data Management: Vector Databases vs. Graph Databases – Periscope Team Blog
[…] attention are vector databases and graph databases. I’ve already written a blog post about the future of Graph Databases. In this blog post, we’ll delve into the differences between these two approaches, […]